Enterprise Code Chatbot Evaluation & Code AI Production Testing
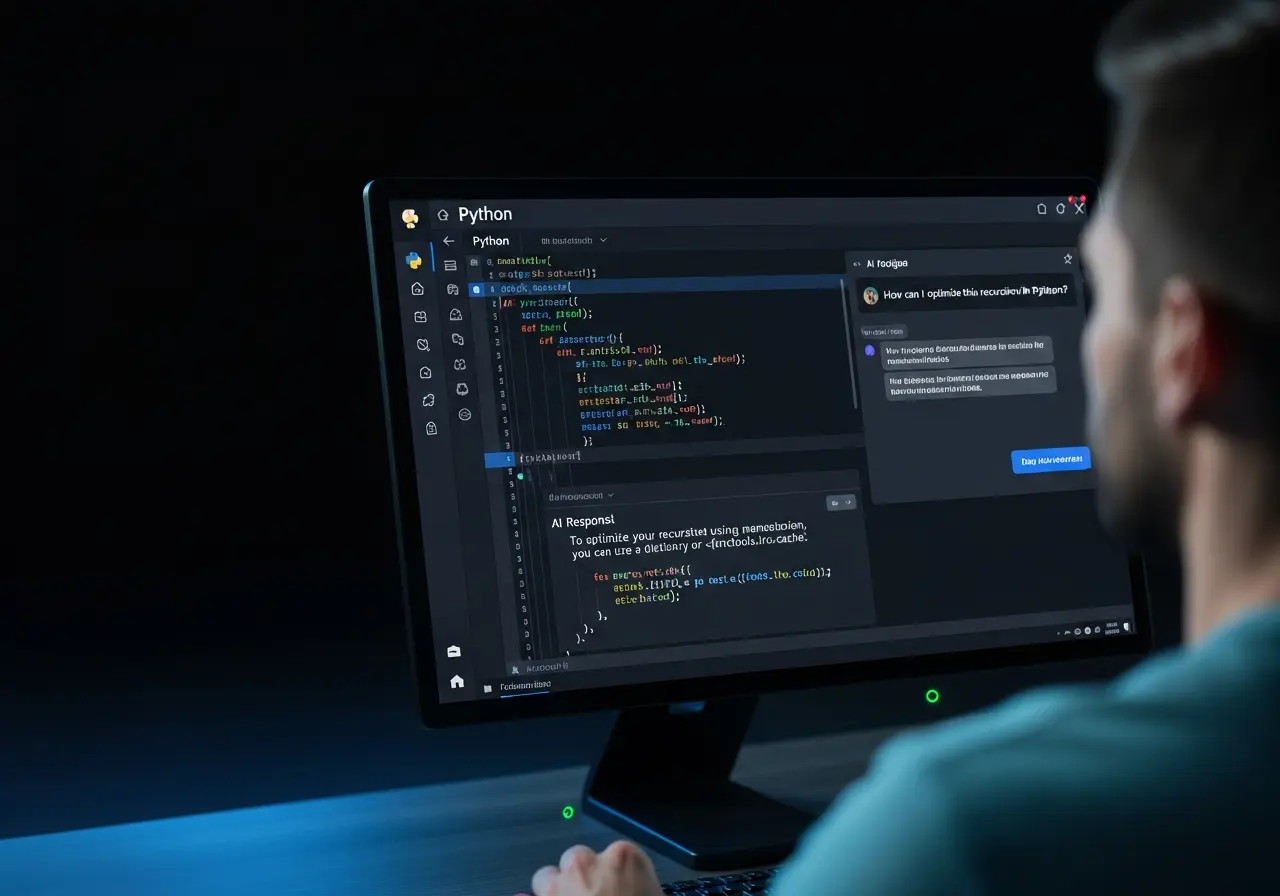
We evaluate GitHub Copilot Chat, GPT-based coding assistants, and developer AI tools under real repository workflows and long-session development environments. Our structured AI System Review (ASR) identifies reliability gaps, hallucinated code, architectural inconsistencies, and developer trust issues before production deployment.
Instead of isolated prompt testing, we simulate full engineering workflows — including debugging sessions, multi-file edits, refactoring tasks, API integrations, and edge-case handling — to assess how your Code AI behaves under real-world pressure.