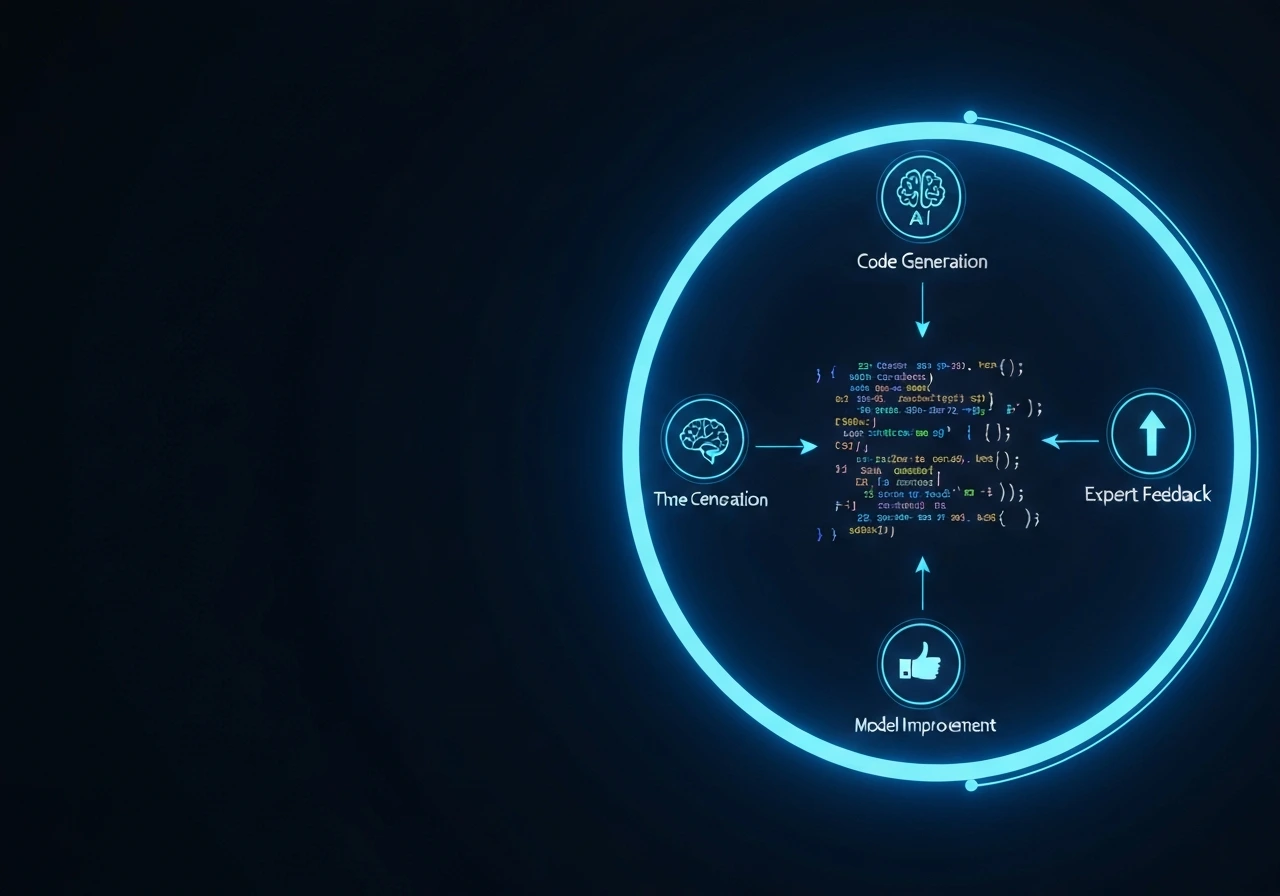
Enterprise Code Improvement & RLHF Evaluation
We evaluate reinforcement learning pipelines and feedback systems used to improve GitHub Copilot, Codex, GPT-based coding assistants, and custom code LLMs operating in production environments.
In code generation systems, poorly designed reward signals can optimize for superficial correctness while degrading architecture quality, security standards, or long-term maintainability. Our structured evaluation identifies reward misalignment, feedback bias, and stability risks before they compound at scale.