Enterprise Code Prompt Optimization & Validation
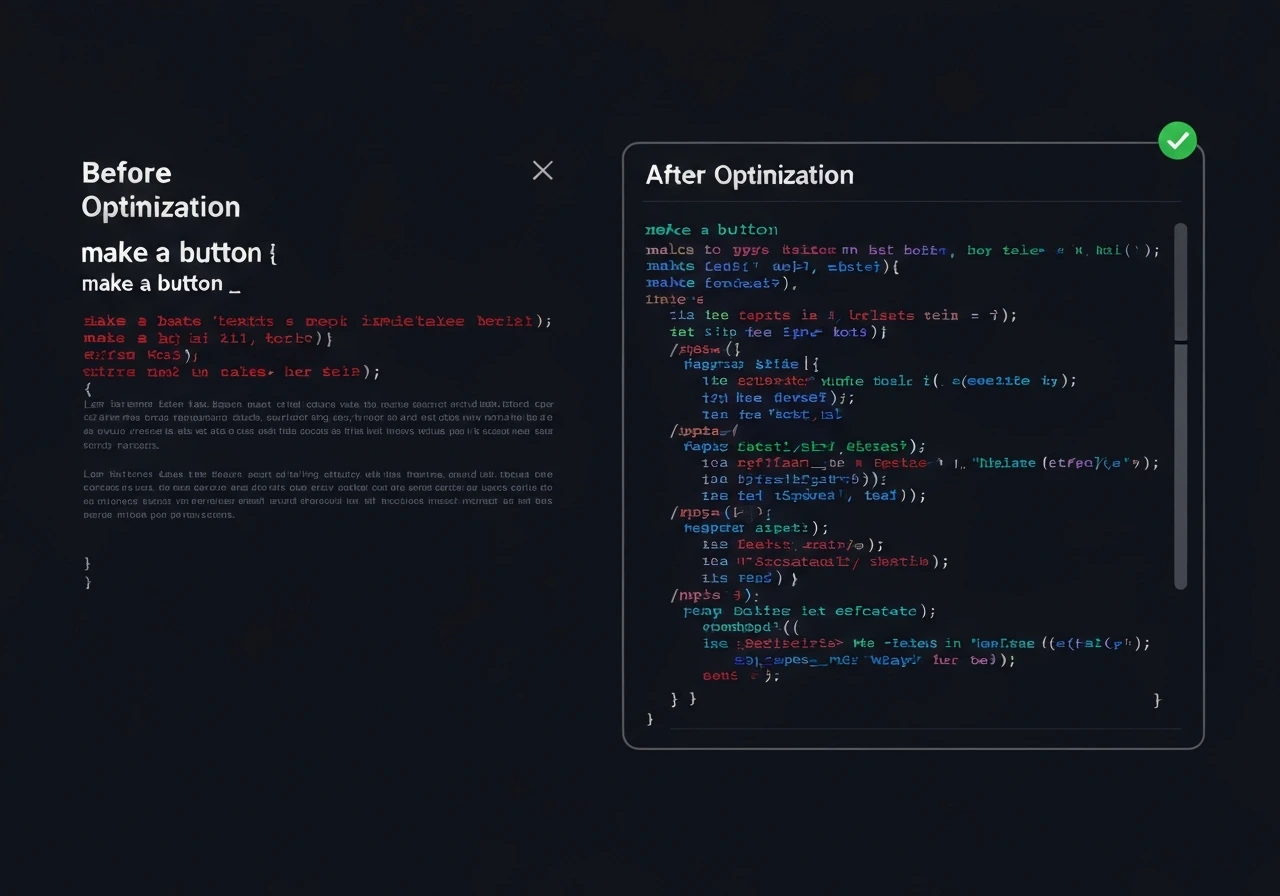
We evaluate and optimize prompts for GitHub Copilot, Codex, GPT-based coding assistants, and custom code LLMs to improve output accuracy, reduce hallucinations, and enhance consistency across real development workflows.
In production environments, prompt structure directly impacts architecture decisions, security patterns, and long-term maintainability. Our structured prompt testing analyzes how comments, instructions, constraints, and context windows influence generated code behavior over repeated sessions.
We deliver clear, actionable optimization guidance through workflow-based evaluation and structured AI System Review reports, enabling your team to systematically improve prompt reliability at scale.